
Now this is going to be a slightly longer article, so get ready.
Neural Networks are built upon our understanding of the human brain, which is a powerful decision making network created of uncountable numbers of neurons connected to each other via dendrites (little nodes at the front and back of a neuron that connect to other neurons).
These neurons connect to one another and send electrical signals to each other. Each neuron then makes a decision based on the input it has received from the signals sent to it. This decision is whether to activate or not, and this is called the “Action Potential”. You can think of this as a LED. If it receives enough input electrical signals, it will light up – otherwise it won’t.
This neuron then sends an electrical signal if it activated through its output dendrites to other neurons in the network which then use that signal as one of their many inputs. This happens so many times per second, every time you have a thought, every millisecond of your existence.
Researchers believed that it would be possible to simulate the brain’s neural pathways in a computer system, and that’s how the concept of a neural network was born. Interconnected artificial neurons making decisions in a computer environment in order to come to a conclusion.
Now this lead to the first question, what was an artificial neuron? What did it look like? How would we perform calculations for this?
Luckily these questions were solved by our good old friend, the sigmoid function. Also known as the logistic function – if you read my previous article on Linear Classification linked here – it outputs the probability of the value of y being equal to one given an input (or the sum of the set of inputs) x.
Now by looking at this we can tell that when there is probability, it is easy to determine which is the more appropriate output, 0 or 1. In this case, in order to make the sigmoid into an artificial neurons, researchers decided to round the value output of the sigmoid functionn. If it was >= 0.5, then it would be 1 (or activated), else it would be 0 (not activated). This allowed the logistic function to mimic the working of an actual neuron.
Additionally, the probability value from the artificial neuron seemed to be something akin to certainty. Due to this researchers realised that if there was an array of these artificial neurons who were all trying to predict whether certain data belonged to different groups or classes, it would not work well if more than 1 activated, as there would be no way of telling the difference between the 2 outputs. Therefore the probability (or certainty) from each artificial neuron was taken in order to demonstrate a level of how sure each sigmoid function was in its classification.
From there a simple max() function would return the output with the highest certainty which could be considered the output of this “neural network”.
Activation Functions
However, as time progressed and neural network research advanced researchers began to encounter certain problems with the sigmoid function. First of all, the output from the sigmoid function was not centered around 0, which was more of a quality of like and simplicity issue which had a big impact of research.
Furthermore the data was not uniform which was important due to the fact that in a deep neural network, neurons connect to more neurons, so the output of one set (or layer) of neurons was the input of another. If the data was not uniform, it posed accuracy and uncertainty issues.
Originally this problem was tackled by the tanh (hyperbolic tangent) function. It has the same shape as the sigmoid function (smooth and differentiable as researchers like it) except it mapped values between -1 and 1 instead of 0 and 1. This allowed more uniformity in the data and centered the data around 0.
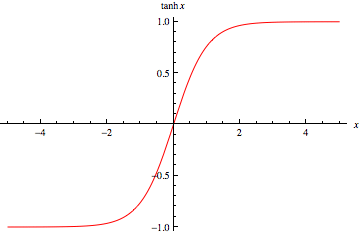
Researchers liked this… until a new problem arose. The vanishing gradient problem. Essentially in short, the vanishing gradient problem was caused by the fact that the derivative of both the sigmoid and tanh functions were really small (max 0.25). And so as the gradient descent function updated the weights and biases of a network (more into this in the next article) the change that it applied to the first layer of neurons was so small by the time it got there, that it barely made a difference at all. This means that the more layers (deeper) a neural network was, the less the earlier layers got trained. This was inefficient, slow, and poorly designed.
Now here comes the savior.
Rectifier Linear Unit, or ReLU for short, was the function which solved the vanishing gradient problem. It kept the imperative functionality of the sigmoid and tanh to make the neural network non-linear, and was not completely differentiable. This is because the ReLU function was defined as follows:

Every value of input greater than 0 was the same, every value below 0 was 0. Simple. It takes and returns the highest value between 0 and the input. Easy. This meant that the derivative of the function was undefined at where the graph touches 0 and that every point above 0 had a non-zero gradient. Because of this, the gradient was always 1 provided the input was above 0. This meant that there would be no compounding of a gradient less than 0, leading to an inexplically small change to the earlier layers in a network.
Since the gradient technically no longer scaled with input, this made the learning rate of a network much more important (this will be covered in an article on gradient descent). The important thing to remember here is that although it may be tough to wrap your head around why the ReLU function works if it just reduces everything below 0 to 0 (I know it took me a while and I still question it sometimes), Deep Learning is an experimental science. That means that if something works, it works. And the ReLU function works, very well. It is the default activation function for Deep Learning models today.
There have been some activation functions which have attempted to solve the “dead neuron” problem where a neuron in a network just has no purpose because the ReLU function repeatedly reduces it to 0 – however that works for the further neurons in the network to make it accurate.
Examples include the Leaky/Parametric Rectifier Linear Unit (LReLU/PReLU) function which had a small ( < 1) positive slope for values lower than 0, the Exponential Linear Unit (ELU) function which used the exponent for values below 0 (this claims to be faster and more accurate than ReLU; however, this is only in certain tasks and is not overall) and therefore it allowed the values to be centered around 0 (researchers love that!). Additionally and finally, there was the Softplus function which created a logarithmic exponent graph between 0 and infinity.

If you’re catching on, this raises another question. Isn’t an artificial neuron with the ReLU activation function instead of a Sigmoid activation function, no longer mirroring an actual biological neuron?
Well yes dear reader! That is a fantastic question. The truth is summed up in 2 points.
- If it works, it works. If it ain’t broke, don’t try to fix it.
- It is actually biologically accurate from another perspective!
See in our brains, when a neuron activates it doesn’t actually encode any information into its action potential like the certainty of the sigmoid function. Instead what neurons use to encode information is the frequency of action potentials. How many times has the neuron activated in a given time frame. For example, if you were to hear a loud sound, neurons would activate rapidly – resulting in a high action potential frequency. On the other hand, a soft sound would not activate the neurons as rapidly, resulting in a low action potential frequency. Therefore, more stimulation means a higher frequency.
Now if we think about the ReLU function, it technically actually outputs the frequency of the action potentials! This would actually make it more biologically accurate than the sigmoid!
This is because the frequency can be any positive value depending on the magnitude/intensity of the stimulation (input). And there is no such thing as a negative frequency, it just doesn’t activate, similar to how the ReLU function returns a 0 if the input (the stimulus) is less than 0.
There is only one issue with this model. That is that the frequency of action potential does not actually grow linearly with the magnitude of the stimulus like the ReLU function models. It is actually a non-linear relationship between intensity and action potential frequency, where action potential frequency grows slower than the intensity of the stimulation. However again, the ReLU function works and it works well.
There was however, an attempt to rectify this issue. This was the Biomodal Root Unit (BRU). This belonged to a family of functions attempting to model an artificial neuron as close to a biological neuron as possible (hence the “biomodel”). However, that is something that I may cover in the future, but I don’t see myself doing it any time soon. If you would like it sooner, drop a comment below and let me know.

2 thoughts on “The Artificial Neuron”